안녕하세요.
첫 포스팅으로 크롤링으로 넷플릭스 인기순위를 가져오기를 해보겠습니다.
들어가기 앞서 크롤링이란 무엇인지 알아보겠습니다.
----------
웹사이트, 하이퍼링크, 데이터, 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것.
크롤링을 위해 개발된 소프트웨어를 크롤러(crawler)라 한다. 크롤러는 주어진 인터넷 주소(URL)에 접근하여 관련된 URL을 찾아내고, 찾아진 URL들 속에서 또 다른 하이퍼링크들을 찾아 분류하고 저장하는 작업을 반복함으로써 여러 웹페이지를 돌아다니며 어떤 데이터가 어디에 있는지 색인을 만들어 데이터베이스에 저장하는 역할을 한다.
출처 [네이버 지식백과]
----------
간단하게 여기서 진행해볼 웹크롤링은 특정 웹사이트에서 내게 필요한 정보들을 갈무리 해와서 사용하는 것으로
생각하셔도 될 것 같습니다.
크롤링을 위해서 필요한 것은 크게
1. 타겟 웹페이지 주소
2. 필요한 정보의 위치
3. 크롤링 개발
(여기선 파이썬에서 BeautifulSoup 라이브러리를 활용해보겠습니다)
1. 타겟 웹페이지 주소
일단 제가 크롤링해볼 싸이트는 각 OTT별 인기순위를 정리해놓은 FlixPatrol 이라는 곳입니다.
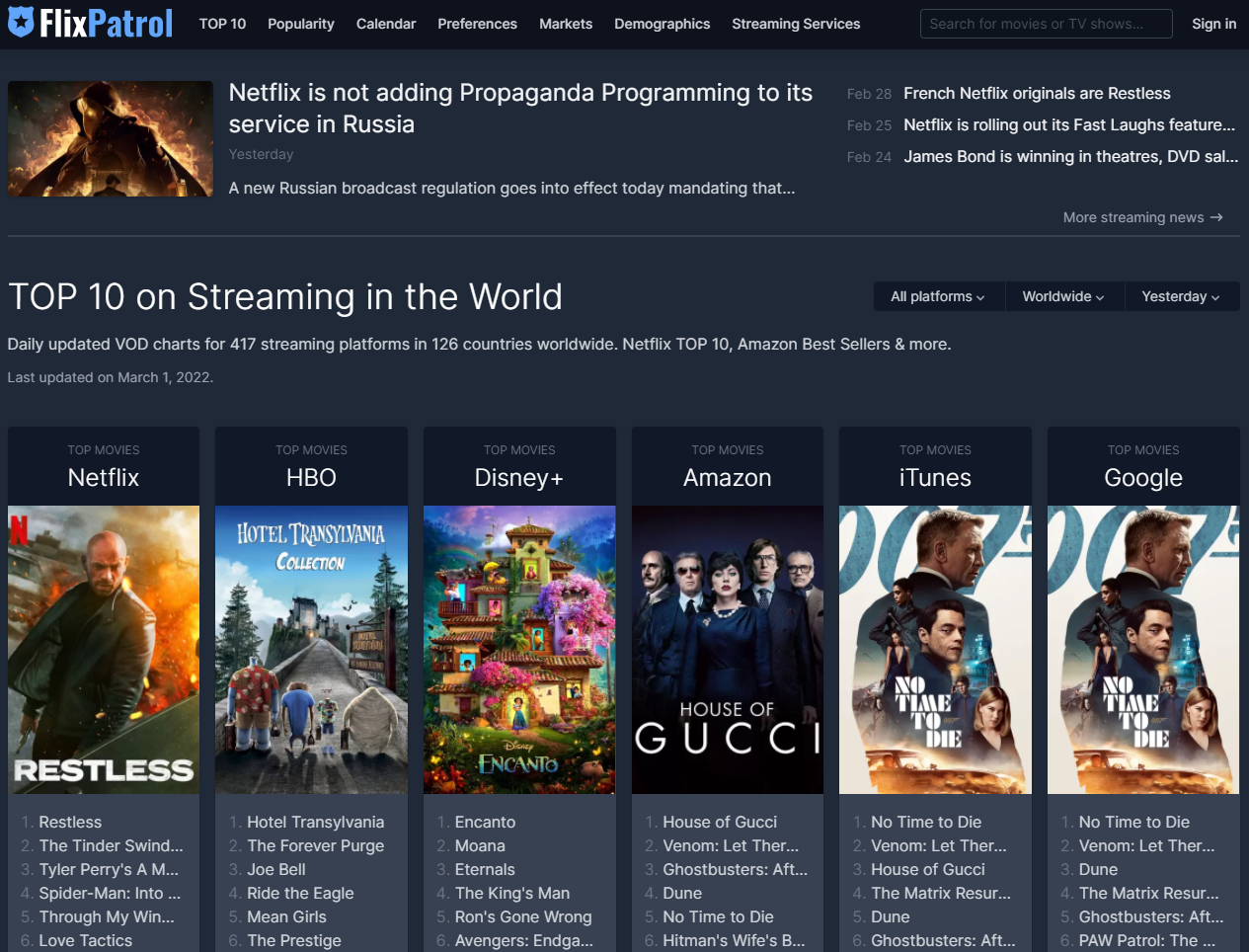
2. 필요한 정보의 위치
여기서 제가 가져올 정보는
https://flixpatrol.com/top10/netflix/world/today/full/#netflix-2
이 메뉴에 있는 순위 정보입니다.
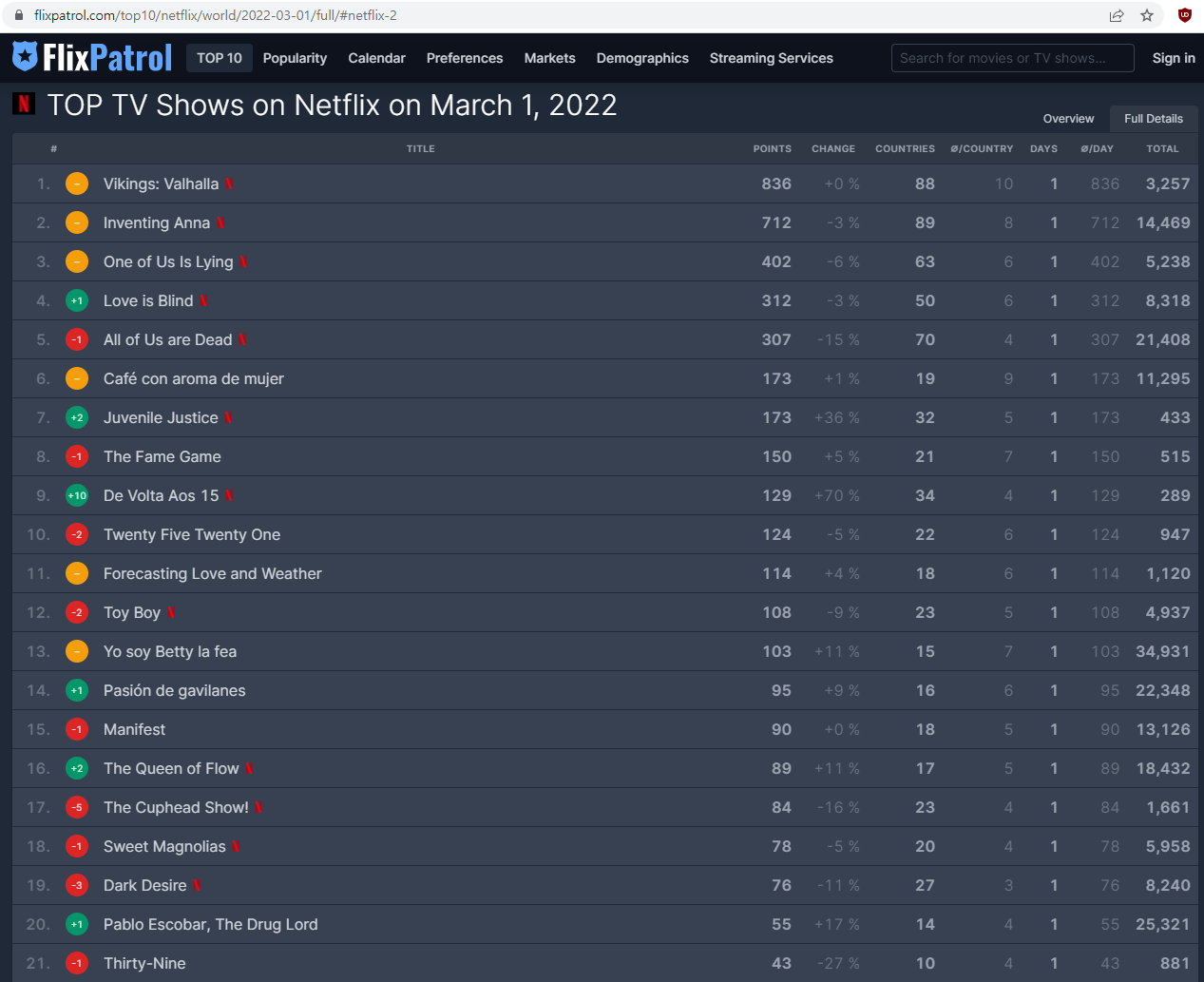
2022년 3월 1일 기준 순위표입니다.
Juvenile Justice(소년심판)
Twenty Five Twenty One(스물다섯 서른하나)
Thirty-Nine(서른,아홉)
반가운 우리나라 작품들도 상위권에 있는 것을 볼 수 있네요.
이처럼 크롤링에 주로 쓰이는 정보들은 반복적이고 많은 정보를 가져올 떄 많이 활용되는 것으로 알고 있습니다.
(ex : 주식정보, 상품 가격정보, 뉴스기사 등)
3. 크롤링 개발
<개발환경 구성하기>
① 파이썬 설치하기
https://www.python.org/downloads/
Download Python
The official home of the Python Programming Language
www.python.org
자신에게 맞는 OS를 확인하고 다운로드 및 설치 진행. (저는 Windows 환경에서 진행했습니다)
완료가 되면 파이썬 자체 개발환경인 IDLE Shell도 있지만, 편의를 위해 Visual Studio Code Tool을 사용했습니다.
② VS Code 설치하기
https://code.visualstudio.com/
Visual Studio Code - Code Editing. Redefined
Visual Studio Code is a code editor redefined and optimized for building and debugging modern web and cloud applications. Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows.
code.visualstudio.com
VS Code 다운로드 및 설치 진행
③ 라이브러리 설치
크롤링을 하기위해 사용할 몇가지 라이브러리 설치작업을 진행합니다.
- BeautifulSoup : 크롤링 기능을 가지고있는 모듈
- requests : 간단한 http 요청을 처리해주는 모듈
- lxml : BeautifulSoup으로 xml을 파싱해주는 모듈
※ 파싱(parsing)
파싱은 어떤 페이지(문서, html 등)에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것을 말한다.
위 라이브러리를 설치하기위해서 pip를 사용하겠습니다.
pip는 파이썬 패키지를 설치하고 관리하는 패키지 관리자(Package Manager)입니다.
pip는 [pip installs packages]의 약자라고합니다. 즉 파이썬에서 우리가 편하게 사용할 모듈, 라이브러리 등을 설치하는 걸 도와주는 프로그램이라고 생각하시면됩니다.
cmd 창에서
pip install beautifulsoup4
pip install requests
pip install lxml
입력하면 pip가 알아서 해당 모듈들을 설치 진행을 하게 됩니다.
(웹 개발 경험이 있으신 분들은 node.js 의 npm과 유사한 개념으로 봐도 되지 않을까 싶습니다)
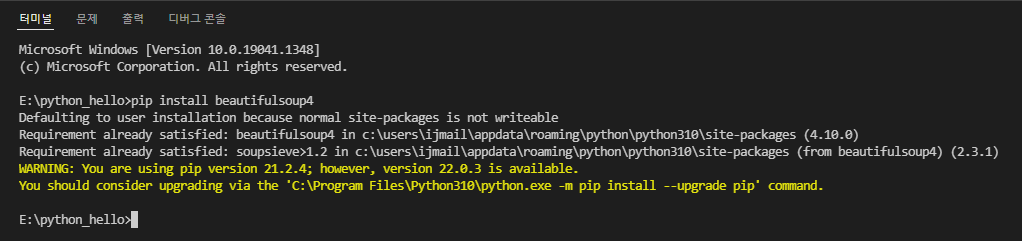
VS Code상의 터미널에서 해당 명령어를 친 화면입니다. 저의 경우는 설치를 했었기때문에 이미 설치가 되어있다고 문구가 나오네요.
이제 이걸로 개발 환경 구성은 마쳤습니다.
<개발하기>
이제 개발환경 구성을 마쳤으니 간단하게 개발하는 과정으로 들어가보겠습니다.
① 페이지 정보 가져오기
import requests #request 모듈을 사용하기 위한 import
from bs4 import BeautifulSoup as bs #BeautifulSoup 모듈을 사용하기 위한 import
#원하는 url 정보를 request 모듈을 통해 가져옴
req = requests.get("https://flixpatrol.com/top10/netflix/world/today/full/#netflix-2")
#text 정보를 html 변수에 담음
html = req.text
#해당 정보를 lxml 모듈을 통해 파싱함
soup = bs(html, "lxml")
#콘솔 출력
print(soup)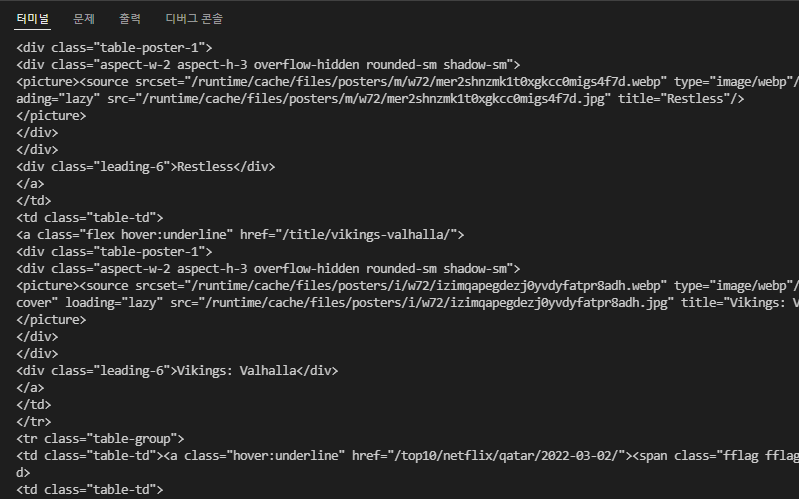
위 처럼 타겟 url의 html 정보를 가져오는 것을 확인할 수 있습니다.
이제 이 많은 것들 중에서 나에게 필요한 정보를 가져오기위한 정제 작업이 필요합니다.
② 원하는 정보 뽑아내기
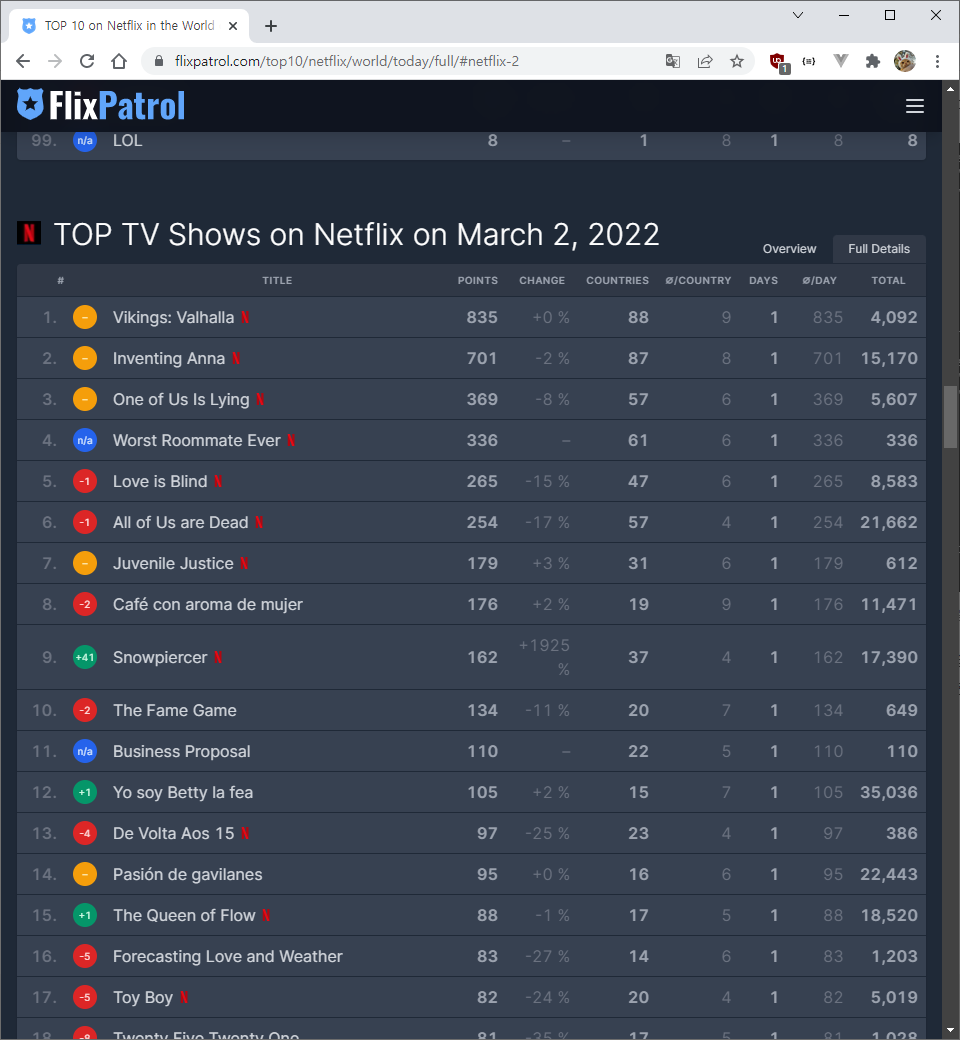
타겟 페이지에서 F12를 누르면 개발자 도구가 나옵니다.(크롬을 사용하였음)
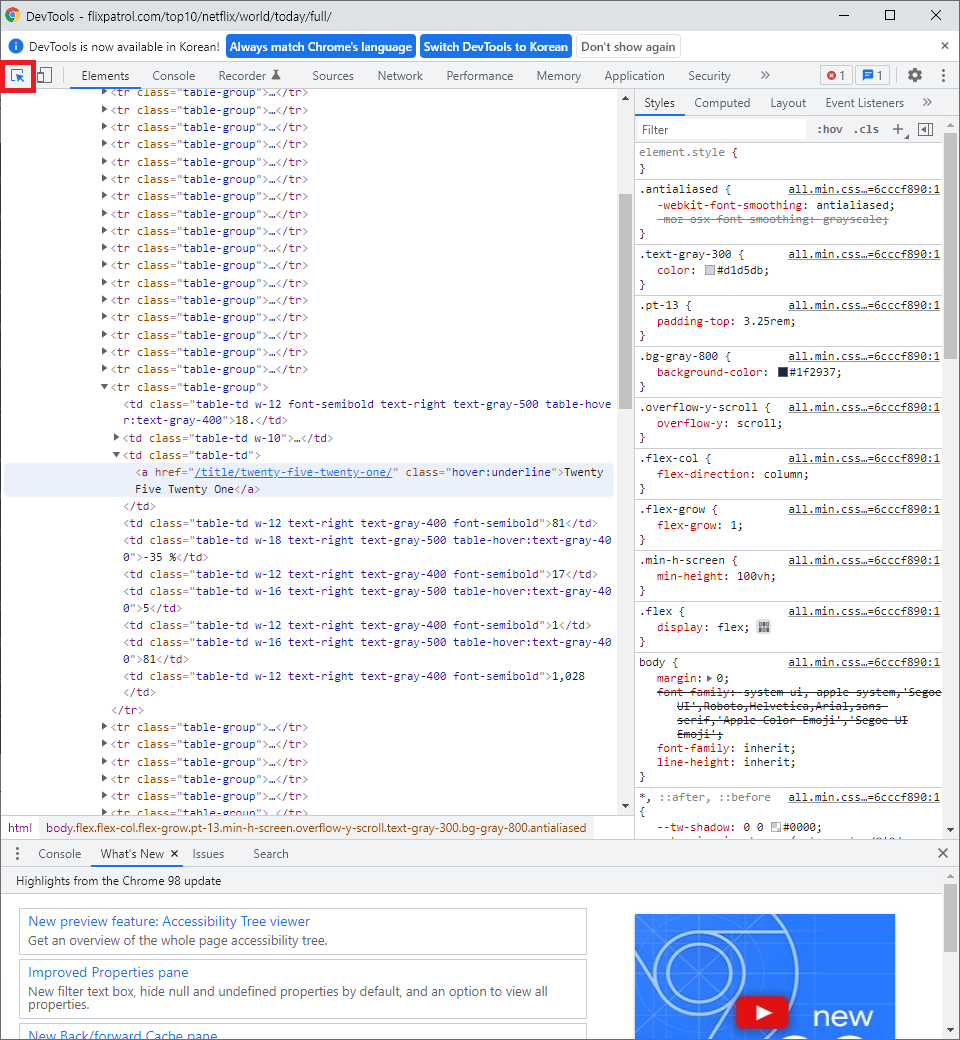
개발자 도구 페이지에서 좌측 상단에 마우스 커서 모양을 선택하시면 타겟 페이지에서 원하는 항목의 내용이 어디있는지 쫒아가볼 수 있습니다. (Ctrl + Shift + C 단축키 활용 가능)
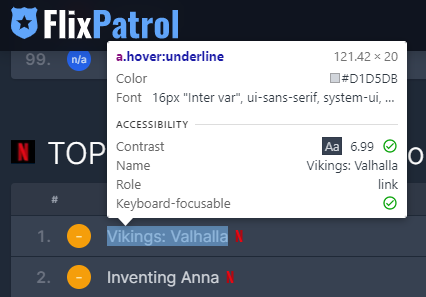
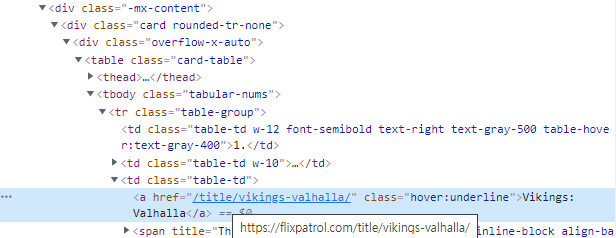
위 처럼 제목부근에 element 선택을 하게 되면 이처럼 해당 엘리먼트 부분으로 이동이 되고 해당 정보를 복사하는 작업을 진행합니다.
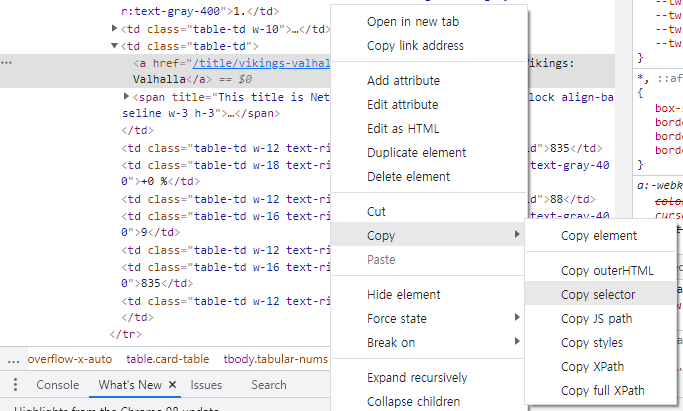
해당 element 우클릭 > Copy > Copy selector 를 누르게 되면
#netflix-2 > div.-mx-content > div > div > table > tbody > tr:nth-child(1) > td:nth-child(3) > a
이런 값이 복사가 됩니다.
이 정보를 사용해서 우리는 규칙적으로 찍히는 정보를 뽑아내는 작업을 진행해야합니다.
일단 먼저 담아두엇던 페이지의 전체정보에서 ( soup = bs(html, "lxml") )
mediaContents = soup.select("#netflix-2 > div.-mx-content > div > div > table > tbody > tr")
위 명령어를 사용해 mediaContents 변수에 해당 위치의 tr 태그 정보들을 담습니다.
import requests
from bs4 import BeautifulSoup as bs
req = requests.get("https://flixpatrol.com/top10/netflix/world/today/full/#netflix-2")
html = req.text
soup = bs(html, "lxml")
#각 줄의 정보를 담음
mediaContents = soup.select("#netflix-2 > div.-mx-content > div > div > table > tbody > tr")
#반복문을 통해 해당 줄에서 내가 필요한 정보를 선택해서 출력
for content in mediaContents:
try:
contentTitle = content.select_one("td:nth-child(3)")
print(contentTitle)
except AttributeError:
continue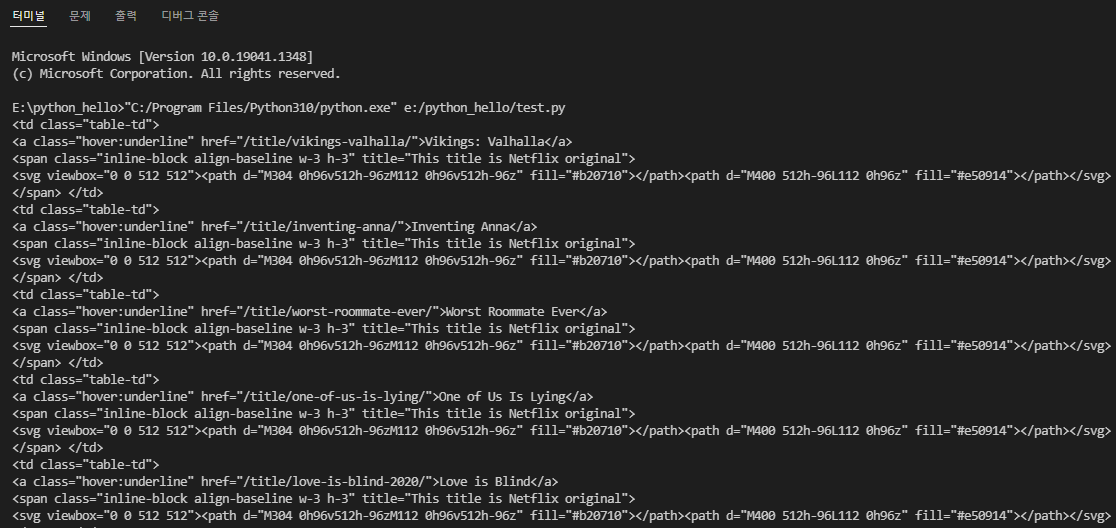
위 실행결과를 보면 <td> 태그들의 정보가 쭉 나열된것을 확인할 수 있습니다. 여기서 우리가 필요한건 제목 정보이니 다시 가져와보겠습니다.
contentTitle = content.select_one("td:nth-child(3)").text.strip().text를 통해서 제목을 가져왔고, 해당 제목들 뒤에 공란이 많이 붙어서 strip()을 통해 공란제거 작업까지 해주었습니다.
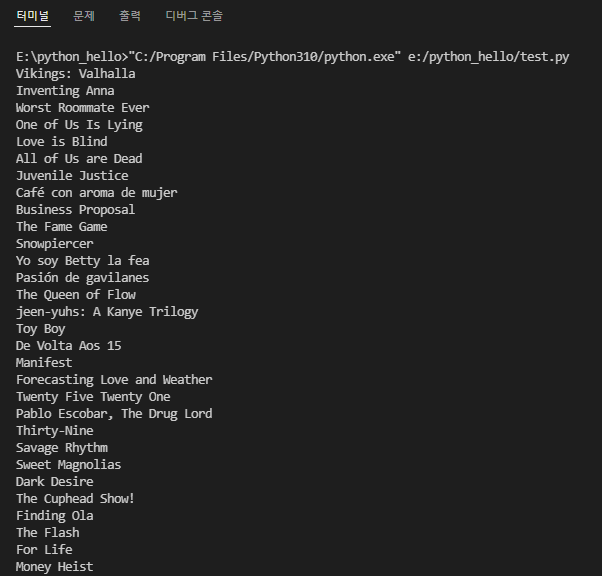
이제 원하던 제목들을 가져오기를 성공하였습니다.
import requests
from bs4 import BeautifulSoup as bs
req = requests.get("https://flixpatrol.com/top10/netflix/world/today/full/#netflix-2")
html = req.text
soup = bs(html, "lxml")
mediaContents = soup.select("#netflix-2 > div.-mx-content > div > div > table > tbody > tr")
rownum=1
for content in mediaContents:
try:
contentTitle = content.select_one("td:nth-child(3)").text
contentPoint = content.select_one("td:nth-child(4)").text
contentChange = content.select_one("td:nth-child(5)").text
contentCountries = content.select_one("td:nth-child(6)").text
contentXcountry = content.select_one("td:nth-child(7)").text
contentDays = content.select_one("td:nth-child(8)").text
contentXday = content.select_one("td:nth-child(9)").text
contentTotal = content.select_one("td:nth-child(10)").text
print(str(rownum) +' : '+ contentTitle.strip() +' | '+ contentPoint +' | '
+ contentChange +' | '+ contentCountries +' | '+ contentXcountry +' | '
+ contentDays +' | '+ contentXday +' | '+ contentTotal)
rownum += 1
except AttributeError:
continue추가적으로 다른 열의 정보도 가져오고, 순번정보도 추가해봤습니다.
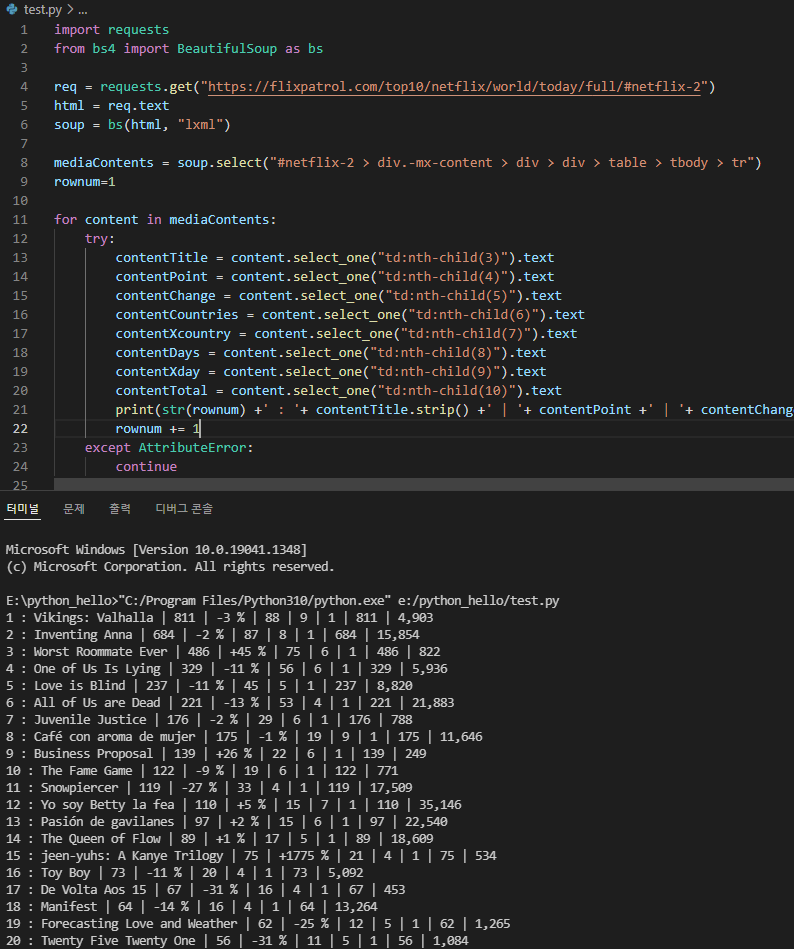
해당 정보들을 활용해서 excel 파일로 작성하는 것도 가능합니다.
이렇게 크롤링을 활용해서 웹에서 보이는 정보를 쉽게 가져올 수 있고, 이를 잘 활용하여 여러방법으로 사용할 수 있을 것 같습니다.
이상으로 포스팅을 마치겠습니다.
※ 해당 웹페이지도 결국 넷플릭스 각 나라별 인기 순위 정보를 크롤링 해와서 보여주는 거라고도 하는거 같네요ㅜ
원하는 정보를 가져와서 어떻게 잘 활용하느냐가 아이디어가 될듯합니다~.
댓글